Il y a quelques mois, Tejas Chopra, ingénieur senior chez Netflix, a ouvert sa facture Claude Sonnet et a ressenti cette frustration désormais familière à beaucoup d’entre nous : 287 dollars pour une session qui ne justifiait clairement pas un tel montant. Près de 90 % de ces jetons n’étaient que du bruit, des logs redondants, des JSON verbeux, des répétitions inutiles que le modèle n’avait pas vraiment besoin de traiter.
Au lieu de payer sans rien dire, il a fait ce que font les vrais développeurs : il a codé une solution. En janvier 2026, il a ouvert le code de Project Headroom. Aujourd’hui, cet outil a déjà permis d’économiser plus de 700 000 dollars collectivement, libéré 200 milliards de jetons, et séduit plus de 8 400 développeurs sur GitHub avec plus de 560 forks.
C’est l’histoire d’un moment charnière en 2026, on réalise enfin que la vraie puissance de l’IA ne vient pas d’envoyer toujours plus de données, mais de les rendre plus denses, plus pures et plus intelligentes. Headroom n’est pas un simple outil de résumé qui risque de perdre des informations. Il est réversible, local et intelligent, une couche d’optimisation qui s’adapte aussi bien au développeur solo qu’à l’équipe qui surveille ses budgets.
Le réveil brutal des géants
L’année dernière, on célébrait encore l’adoption massive d’outils comme Claude Code. Chez Uber, l’enthousiasme a été tel que près de 5 000 ingénieurs ont adopté l’outil à 84 %, générant jusqu’à 70 % du code via IA. Résultat ? Le budget annuel 2026 a été épuisé dès avril, avec certains ingénieurs dépassant les 2 000 dollars par mois.
Chez Microsoft, l’histoire est tout aussi parlante, après avoir ouvert l’accès à des dizaines de milliers d’employés, l’entreprise a dû annuler la majorité des licences Claude Code dans sa division Experiences & Devices avant fin juin 2026, les factures dépassant largement les prévisions.
Ces anecdotes ne sont pas des échecs isolés. Elles révèlent un paradoxe cruel, plus l’IA devient performante et accessible, plus on l’utilise, et plus elle coûte cher. C’est le paradoxe de Jevons revisité pour l’ère des jetons, l’efficacité nourrit l’abondance, qui à son tour fait exploser la consommation globale.
Le coût caché du cache KV : pourquoi les factures explosent
Cette explosion de coûts s’explique en grande partie par la mécanique interne des modèles. Lors du décodage, le modèle génère un jeton à la fois. Chaque nouveau jeton doit tenir compte de tous les précédents via le mécanisme d’attention. Sans optimisation, cela crée un recalcul redondant en croissance quadratique.
Le cache KV (Key-Value cache) résout cette redondance : il stocke les vecteurs de clé et de valeur déjà calculés pour les relire linéairement. Mais ce cache vit en mémoire et grandit avec chaque jeton généré, devenant un véritable goulot d’étranglement, surtout avec des contextes longs.
L’illustration ci-dessous, intitulée The KV Cache Tax, montre parfaitement ce phénomène sur un modèle Llama 3.2 avec du matériel H100 :
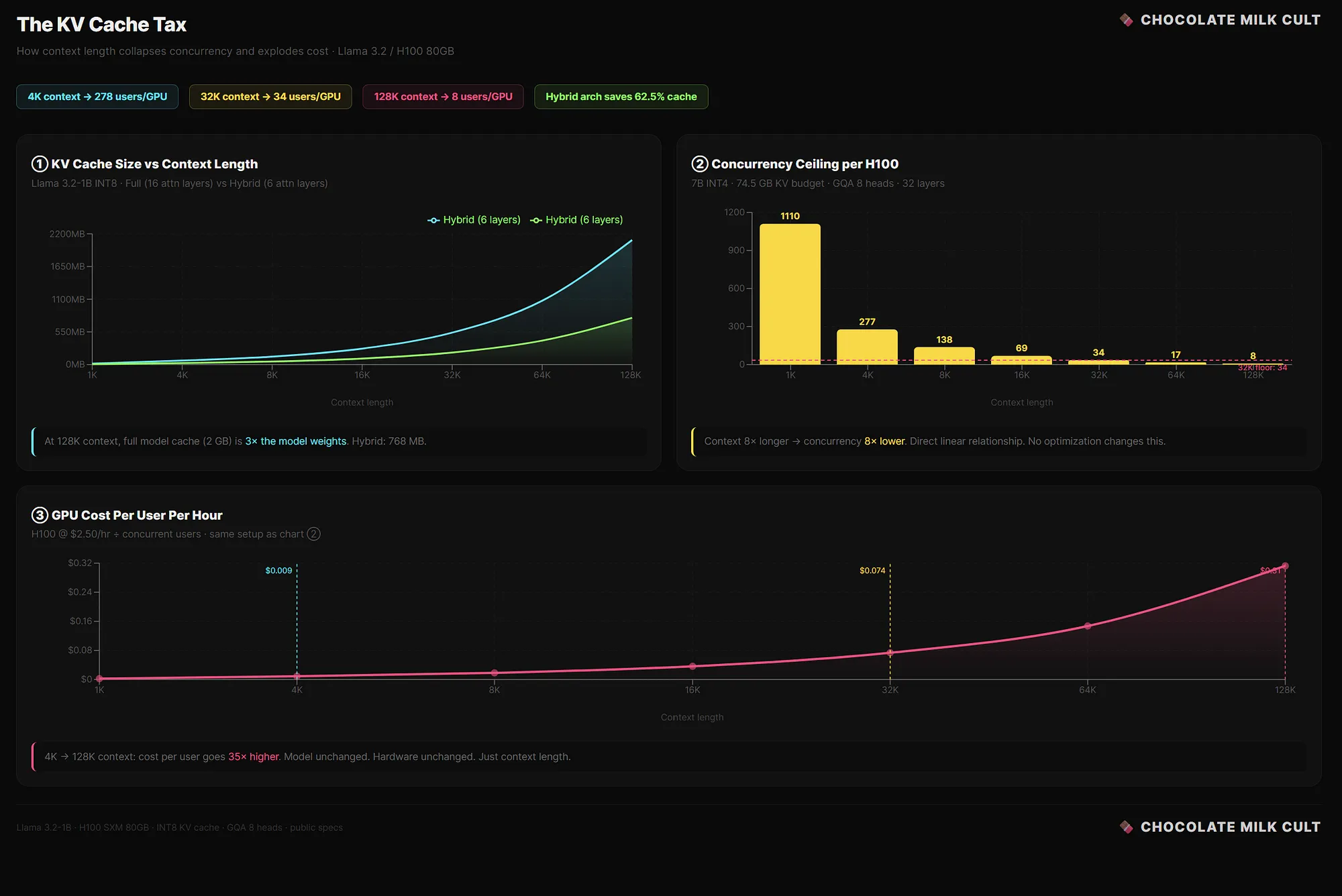
On y voit :
- Graphique 1 : La taille du cache KV augmente fortement avec la longueur du contexte (courbe bleue et verte qui montent sensiblement de 4k à 128k jetons).
- Graphique 2 : Le nombre d’utilisateurs simultanés par GPU chute dramatiquement (de 277 utilisateurs à 4k jetons, jusqu’à seulement 8 utilisateurs à 128k jetons).
- Graphique 3 : Le coût par utilisateur et par heure augmente de façon exponentielle (x35 entre 4k et 128k jetons).
Headroom agit précisément en amont de ce problème : en compressant les jetons inutiles avant qu’ils n’atteignent le modèle, il réduit drastiquement la taille effective du contexte, limite la croissance du cache KV, améliore la concurrence et fait baisser les coûts réels, tout en maintenant (voire en améliorant) la qualité des réponses grâce à une réduction du bruit.
Le piège invisible du Context Rot
Derrière ces factures se cache un phénomène encore plus insidieux : le Context Rot (pourriture du contexte). Dans leur étude marquante de juillet 2025, l’équipe de Chroma a testé 18 modèles de pointe, dont GPT-4.1, Claude 4, Gemini 2.5 et Qwen3. Résultat, la performance ne s’améliore pas linéairement avec la longueur du contexte, au contraire, elle se dégrade. Les modèles privilégient le début et la fin du prompt, ignorent le milieu et se laissent distraire par du bruit sémantique.
C’est comme si votre cerveau, submergé d’informations, commençait à oublier les éléments au milieu de la conversation. C’est exactement ce qui arrive. Ajouter des milliers de jetons ne rend pas l’IA plus performante, parfois, cela la rend plus confuse, et surtout plus chère.
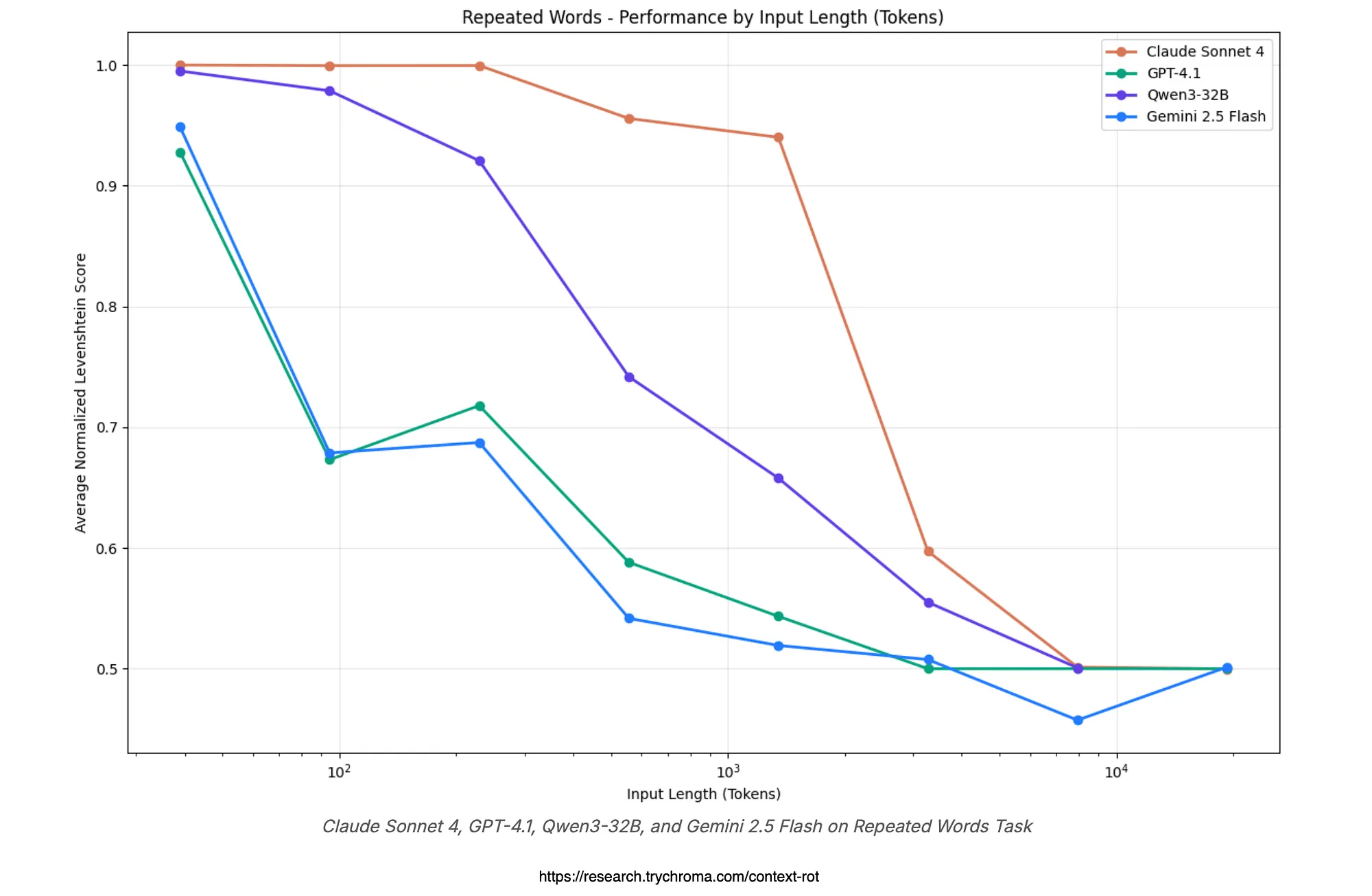
Graphique du Context Rot issu de l’étude Chroma : la précision chute de façon dramatique à mesure que le contexte s’allonge.
L’étude montre que les LLM obtiennent de meilleurs résultats lorsque les informations pertinentes sont au début ou à la fin. Quand elles se trouvent au milieu de contextes longs, la récupération devient nettement moins fiable. Des fenêtres contextuelles plus grandes ne sont donc pas une solution magique : la conception intelligente bat souvent la force brute. Cette dépendance rend également vos applications vulnérables aux fluctuations de prix des jetons et aux dépréciations de modèles.
Headroom entre en scène
C’est là que Headroom, de part son élégance technique, parviens avec une beauté presque poétique à donner plus de clarté aux contexte. Installé en local, il agit comme un filtre intelligent, un intermédiaire discret entre vous et le modèle.
Il analyse tout ce qui va être envoyé, logs serveurs, sorties d’outils JSON, chunks RAG (Retrieval-Augmented Generation, génération augmentée par récupération), historique de conversation, et applique une compression réversible et sans perte.
Le CacheAligner est particulièrement malin : il détecte et stabilise les éléments changeants (dates, UUID, métadonnées dynamiques) qui empêchent normalement le caching côté fournisseur (comme chez OpenAI ou Anthropic). En rendant le contexte plus stable et prévisible, il permet une meilleure réutilisation du cache existant, réduisant ainsi les appels répétés et les coûts associés.
Des routeurs intelligents choisissent ensuite l’algorithme adapté : AST pour le code, squashing statistique pour le texte, DOM pour les structures JSON.
Le joyau reste le CCR (Compress Cache and Retrieve – Compression, Cache et Récupération) : le modèle reçoit une version allégée, légère, presque épurée. S’il a besoin d’un détail précis, il interroge le cache local (Redis pour la performance ou SQLite pour la simplicité) via MCP pour le récupérer intact, ainsi pas de perte, juste de la pureté. Un feedback loop ajuste en temps réel l’agressivité de la compression.
Les chiffres sont éloquents, jusqu’à -90 % sur les logs, -70 % sur les JSON d’outils, -92 % sur des recherches code massives (de 17 765 à 1 408 jetons). Des utilisateurs rapportent un gains moyens de 60 à 95 % de jetons en moins, avec des réponses souvent plus précises grâce à la réduction du bruit.
Dans un monde où les workflows agentiques multiplient les appels et où les contextes atteignent des centaines de milliers de jetons, Headroom offre bien plus que des économies. Il apporte une forme de sobriété intelligente, moins de gaspillage, plus de focus, une latence réduite qui rend enfin fluides les applications vocales ou en temps réel. Il transforme un centre de coût en levier de compétitivité tout en réduisant l’empreinte carbone.
Pour passer à l’action
Le repo officiel est votre point d’entrée : github.com/chopratejas/headroom. L’installation est rapide (pip install headroom-ai), le proxy se lance en quelques commandes. Commencez toujours par des tests légers sur des workflows non critiques pour mesurer les jetons économisés, la latence et la similarité des réponses (via cosine ou F1). Activez systématiquement le CCR pour garantir une compression réversible et éviter toute perte d’information.
Pour les setups avancés, intégrez-le en sidecar et combinez-le avec du semantic caching (mise en cache sémantique) et du routing de modèles (cheap vs premium). Vous obtiendrez ainsi un ROI rapide sur vos workflows existants, une différenciation compétitive grâce à des coûts maîtrisés, et une réduction notable de votre empreinte carbone.
Bien sûr, restez vigilant sur des données sensibles (finance, médical, légal), une mauvaise configuration sans CCR actif peut introduire des erreurs subtiles et créer des risques juridiques ou de décisions erronées. Le stockage local (Redis ou SQLite) demande une attention particulière à la conformité RGPD. Comme l’outil est encore jeune (v0.22), testez rigoureusement et contribuez à la communauté pour accélérer les extensions (finance, multimédia). L’inconvénient principal reste le temps d’intégration initial, mais il est vite amorti par les économies générées.
Headroom nous rappelle que la vraie élégance technologique n’est pas dans l’excès, mais dans la maîtrise. Dans cette capacité à tailler le superflu pour révéler l’essentiel. Il illustre parfaitement la maturité de l’écosystème IA open-source en 2026, on ne se contente plus d’utiliser plus de tokens, on les rend plus intelligents et moins chers. Que vous soyez juste curieux des tendances ou prêt à optimiser vos workflows, cet outil mérite d’être testé.
Allez explorer le repo, lancez un test sur une de vos tâches quotidiennes, et revenez partager votre expérience en commentaires. C’est en échangeant ces petites victoires que nous construisons collectivement une IA plus durable et plus intelligente. La communauté avance mieux ensemble.
// // COMMENTAIRES (0)